
News & Columns


検査体制の制約に加えて、無症状患者の存在や30~50%に及ぶ偽陰性など、新型コロナウィルスの感染者数の現状や動向を的確に把握するのは容易なことではありません。しかし、このような難題にシステムモデルを活用する試みが最近、システムダイナミクス学会誌にて発表されました。
前回に引き続き、ヴァージニア工科大学のGhaffarzadegan氏MITのRahmandad氏による論文「Simulation-based estimation of the early spread of COVID-19 in Iran: actual versus confirmed cases」の主要ポイントを紹介します。
5. 感染モデルのシミュレーションと実データ比較(1)
前回の記事で、感染者数・死亡者数の拡大、抑制に加えて、検査体制を充実させるダイナミクスを説明するシステムモデルにおいて、報告数ベースのデータから実態ベースの感染者数・死亡者数を推測するシミュレーションするモデルを紹介しました。
図3:国レベルでの感染シミュレーションモデル
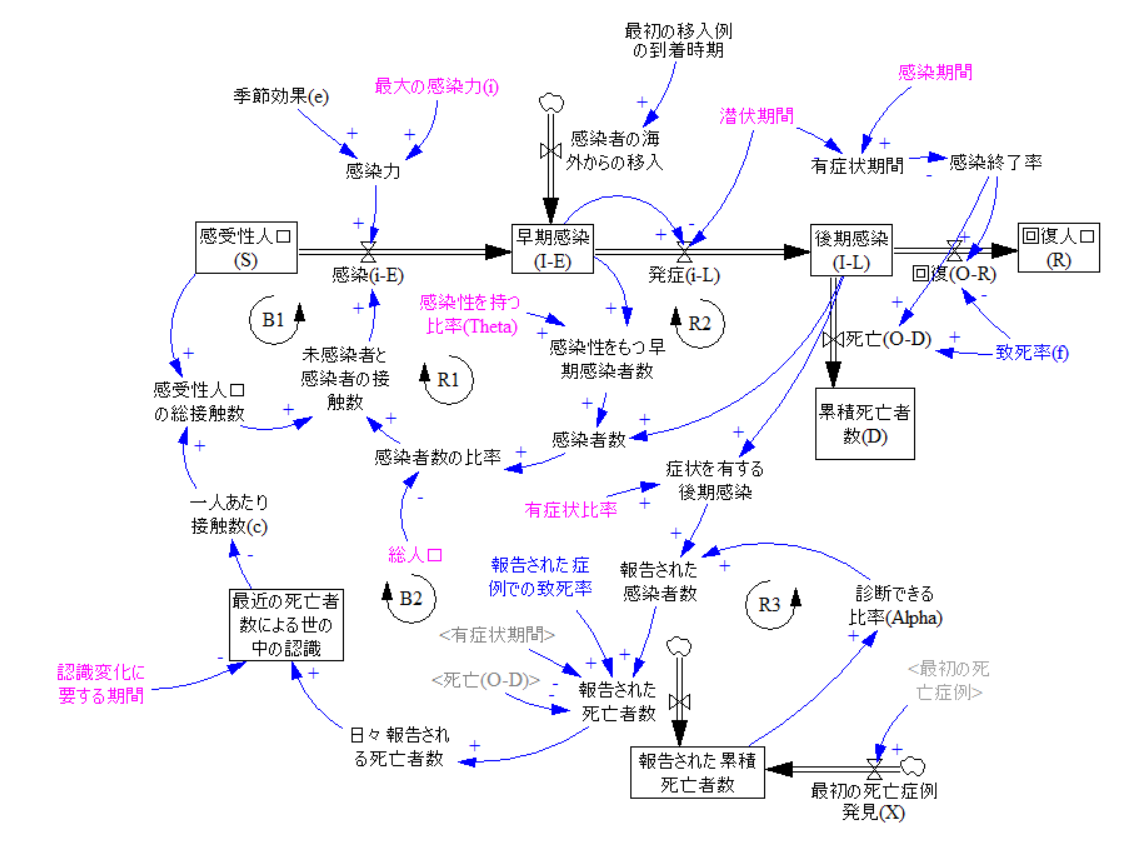
(出典:Ghaffarzadegan & Rahmandad, "Simulation-based estimation of the early spread of COVID-19 in Iran: actual versus confirmed cases"、翻訳はチェンジ・エージェント社)
論文筆者らは、イランにおける2月18日から3月20日の感染状況のデータや独立した研究報告などのデータをもってモデルを構築、パラメーター較正に活用しています。下記グラフ(a)(b)では、シミュレーション結果と実データなどの比較が示されていますが、誤差の度合いを示す平均平方二乗誤差率は、感染者数16%、回復者数26%、死者数5%とまずまずの適合です。
図4:イランの感染状況に関するシミュレーションI(2月18日~3月20日)
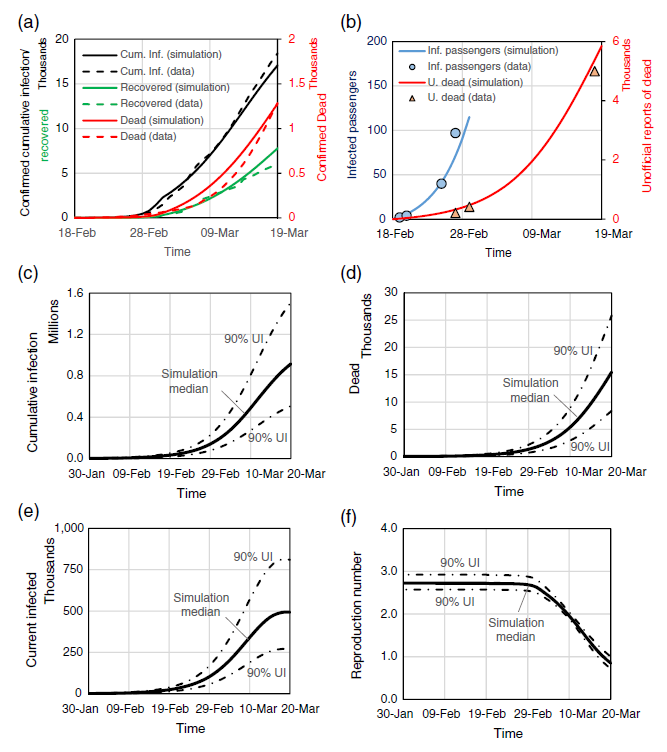
(a) 黒:報告累積感染者数(千人あたり)、緑:回復者数(千人あたり)、赤:報告死者数(千人あたり)
(b) 青:渡航者に占める感染者数、赤:非公式な死者数(千人あたり)
(c) 累積感染者数(百万人)
(d) 死者数(千人あたり)
(e) 現在の感染者数(千人)
(f) 実効再生産数
(出典:Ghaffarzadegan & Rahmandad, "Simulation-based estimation of the early spread of COVID-19 in Iran: actual versus confirmed cases")
確率的に最適なパラメーターを設定したこのシミュレーションの結果では、3月20日現在の無症状・軽症を含めた実際の感染者数(グラフc)は918,000人(90%信頼区間:508-1,500千人)と推定、報告された19,644人に対して26~76倍であったと分析しています。検査のカバー率のデータは存在せず、不完全な補完データからの分析であるため、推定の幅が大きいですが、それでも、信頼区間の下限においても、報告値の26倍の推定となるのは、相当数のモレがあることを示唆します。筆者らの考察では、モデル発表よりも後に公表された4月下旬にギーラーン州で行われたランダムサンプルの抗体検査から、市民の21-33%が感染したとの研究に対して、この全国ベースのモデルのデータから感染報告者数で類推した感染者比率は3-4%でしたので、このモデルですら過少見積もりをしている可能性があります。報告ベースの感染者数の過小は相当な規模であったことがうかがえます。
死亡者数(グラフd)について、3月20日現在1,433人の報告数に対して、15,485人(90%信頼区間:8.4-25.8千人)と6~18倍であったと推定しています。筆者らは、過去5年間の死亡統計について、感染の蔓延した地域とそうでない地域の比較からベースライン(死荷重)を設定し、感染期の死亡者数超過が報告数の約7倍であり、推定の信頼区間内であることを確認しました。この数字はすべての死因を含めた上での正味超過でした。誤差要因として、外出制限によってイランの主要な死亡要因である大気汚染と交通事故の減少分が考えられますが、同時に医療供給体制の逼迫により他の疾病等の死亡が増加する可能性も考慮に入れる必要があります。
実効再生産数(グラフf)について、当初は推定2.72と極めて高いレベルで推移しますが、2月下旬から死者数の増加に従いリスク認識し、接触数を推定74%削減することによって、3月20日までに1を切るレベルまで低下しています。これがその後感染ピークを迎える予兆を示すものであり、現実のデータでも裏付けられました。
6. 感染モデルのシミュレーションと実データ比較(2)
筆者らは、さらに5月14日までの55日分のデータを入手し、前述の3月20日までのデータで構築したモデルのシミュレーション結果との比較を行いました。下記のグラフは、上から報告ベースの感染者数、死亡者数、回復者数、そして、左側は累積、右側は日ごとのデータを示します。また、黒がシミュレーション結果で、赤は後に実際に入手されたデータです。
図5:イランの感染状況に関するシミュレーションII(2月18日~5月14日)
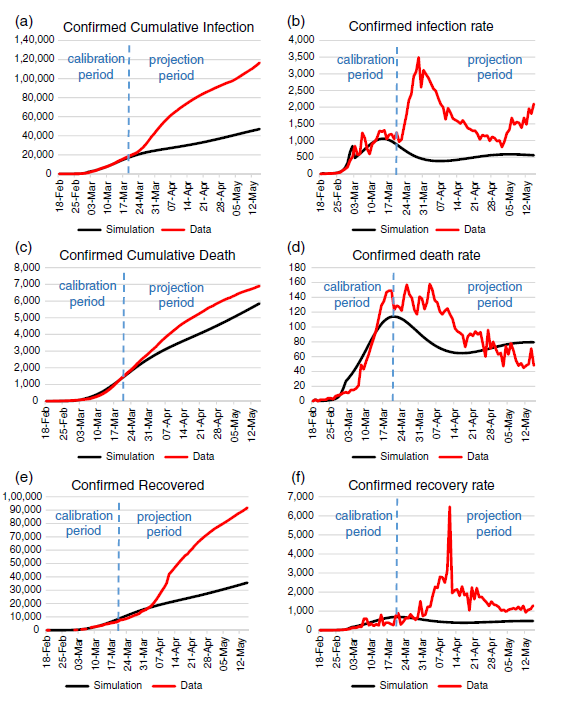
(a) 報告累積感染者数
(b) 報告新規感染者数(1日あたり)
(c) 報告累積死者数
(d) 報告死者数(1日あたり)
(e) 報告累積回復者数
(f) 報告回復者数(1日あたり)
(出典:Ghaffarzadegan & Rahmandad, "Simulation-based estimation of the early spread of COVID-19 in Iran: actual versus confirmed cases")
結果を見ると、おおまかなダイナミクスは外していないですが、数値予測の難しさを反映して大きなずれもあります。複雑なシステムにおいて、過去は未来の延長線上でないことはしばしばあります。予測モデルの策定にあたっては、累積感染者数のデータの実績をもとに「曲線回帰」を行って傾きの推測を行うアプローチがしばしばとられます。しかし、追加データによって傾きの推定が上下動しやすく、また、累積の正規分布による回帰は初期に過大な見積もりしやすく、さらには政策や施策によるコントロールを反映することが難しくなる傾向があります。アメリカでよく政府やメディアに引用されるワシントン大学の保健指標評価研究所(IHME)の予測分析もまた、累積患者数の曲線回帰手法に頼っているためにデータを更新する都度推定値が上下に振れる傾向がありました。また、その報告をよしとしない政治家や市民の攻撃を受ける原因になっています。
正規分布ではなく初期にはSEIRモデルやロジスティクス曲線モデルなどの基本モデルをベースにしながら、政策や行動変化などのフィードバック効果を加えること、また、累積(ストック)に対してではなく、1日あたり新規、回復、死亡などのフローに焦点あてることによってモデルの信頼性は高まるでしょう。
さらに、感染の早い段階において、さまざまなパラメーターのデータへのアクセスが限られ、新型ウィルスや社会の反応の仕方もわからないことが多くあるものです。こうした場合には、シンプルなモデル構築に始まり、実際の結果データを収集して振り返ることで、見逃していた変数やフィードバックを発見したり、あるいは、出現してくる非線形の変化を理解することができるようになります。
論文筆者らも、常に限られた過去及び直近のデータしか無い意思決定者の状況を鑑み、追加データによってすぐにパラメーターを較正し直すのではなく、構造的、質的な視点についての学習プロセスをこの論文の中で再現しています。具体的には、誤差の原因について、以下のような考察をしています。
○イランでは3月下旬から新年となるため、里帰りなど相当の人口の移動が予測されたが、論文の焦点が早期のデータが少ない時期にいかに状況を把握するかにあったのであえて追加しなかった。
○検査体制の拡充の影響について、感染拡大期と安定期では異なった影響が出た。(安定期には過少見積もりとなった)
○死者数(c, d)の誤差は少なめなのに対して、感染者数(a, b)と回復者数(e, f)の誤差が大きい。検査数の増加によって、イランではより症状の軽い感染者数の発見がモデルの想定以上に増えていた可能性がある。
○回復者のデータ(f)において、4月の中旬にピークが見られるが、これは新年による感染増の影響のフォローアップあるいは症例完了に関する出来事と考えられる。
システムモデルを使ったシミュレーションは、検査体制の増加や診断される感染者プロフィールの変化など、すでにある要因間の変化を修正したり、あるいは、社会的な行事や政策・慣行の変化などを外因として導入することが可能です。ただし、むやみに考えられる外因を追加するのではなく、情報の追加が全体としての意思決定の質をあげるかを吟味しながら、取捨選択していくのがよいでしょう。
7. 感染モデルのシミュレーションと実データ比較(3)
筆者らは5月中旬から7月1日までのシミュレーションを、季節効果の想定3パターン(S1~S3)と政策実行の強度2パターン(P1、P2)を掛け合わせら6つのシナリオで行いました。
S1:季節効果無し(ステータスクオ)
S2:5月1日から6月1日までに実効感染力が半減、その後一定
S3:5月1日から6月1日までに実効感染力が75%減、その後一定
P1:政府広報やメディア報道による市民、事業者、行政らの行動変容(ステータスクオ)
P2:政府によるより強力な制限要請または命令により接触数が50%削減
結果は以下の通りです。
図6:イランの感染状況に関するシミュレーションIII(2月18日~7月1日)
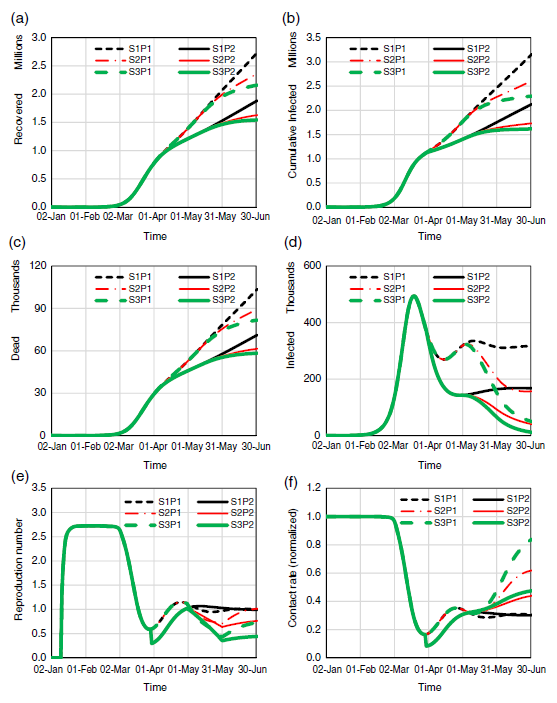
(a) 累積回復者数(百万人)
(b) 累積感染者数(百万人)
(c) 累積死者数(千人)
(d) 1日あたり新規感染者数(千人/日)
(e) 実効再生産数
(f) 接触数(感染前ベースライン=1で標準化)
(出典:Ghaffarzadegan & Rahmandad, "Simulation-based estimation of the early spread of COVID-19 in Iran: actual versus confirmed cases")
ここでは実効再生産数(グラフe)と接触数(グラフf、ベースラインを1で標準化)に注目して読み始めるとよいでしょう。
接触数は3月から4月にかけて急激に減りますが、感染者数や死亡者数の伸びが緩やかになるにつれて、経済活動再開などによって増えます。この際、グラフでは季節効果の高いシナリオにおいて、接触数が上がっていることに注目ください。S3P1シナリオでは、接触数が増えているにもかかわらず、再生産数や感染者数、死亡者数はもっとも低いシナリオになっています。これは、感染について認識するリスクが下がり、ある意味気をつけながらも活動を進めている状態です。逆にS1、S2のシナリオでは、感染者数や死者数がある程度出ていることによって、接触数を低いレベルに抑え続けることが必要となります。
このシミュレーションシナリオは示唆的です。なぜなら、カーブとしてS3P1シナリオは、接触数、つまり経済活動他の社会活動をある程度高めつつも、実行再生産数が抑え、感染者数や死亡者数の推移も他の疾病などと同程度に許容できるレベル以内に収束していけることを示しているからです。
現在のところ、季節効果があるか否かは仮説でしかありません。もし仮にあったとしても、秋冬には季節効果は逆効果に作用することを意味していますので、そこに頼るのは次善策でしかありません。では、どのように接触数を増やしながらも実効再生産数を減らすことができるでしょうか? あるいは、人流を増やしながらも、必ずしも接触しないレベルにもっていくことができるでしょうか? これこそ、「新常態」の事業活動や教育、文化形成の中心的なテーマだと思います。また、モデルに関しても、実効再生産数を分解したさまざまな要因を加え、コンタクトトレーシング戦略と合わせて、戦略を策定し、指標のモニタリングが求められるところかと思います。
さて、論文には記載されていませんが、イランの累積及び新規感染者数の実データ(報告ベース、7月18日まで)とシミュレーションを比較してみましょう。シミュレーション結果では、それぞれ(b)、(d)に対応します。(シミュレーションでは、7月1日までであること、また、報告ベースではなく、診断されなかった症例を加えた実態ベースの推測であることに留意ください。)
図7:イランの累積及び新規感染者数(報告ベース、2月15日~7月18日)
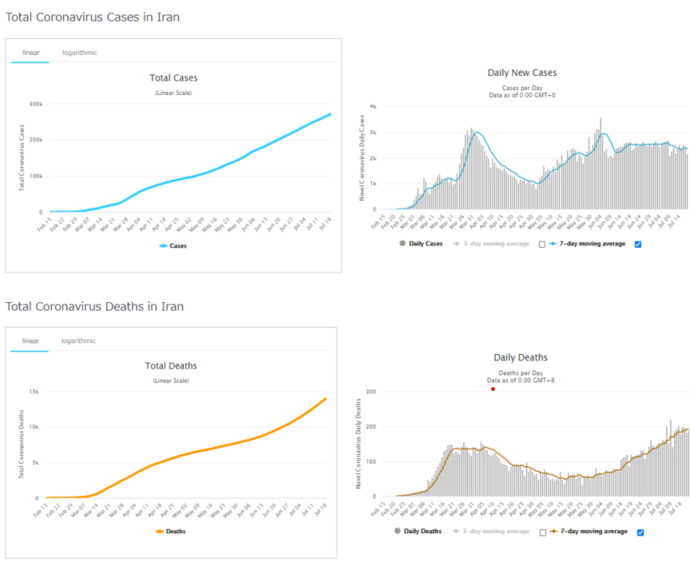
(データ:http://worldometers.info/coronavirus)
これらを比べても、ダイナミクスはシミュレーションシナリオの範囲であると読み取れます。
カーブの形だけ見ると、一見「S1P1」の季節変動がなく、リスク認識から自発的な行動変化が起こるシナリオのようにも見えます。しかし、このシナリオでは実態ベースで30万人/日の新規感染のレベルにありますが、報告ベースでは2-3千人/日のため、100~150倍の乖離があります。検査体制の拡充などにより、3月までの46倍よりも乖離が縮小していくことが期待されることから、「S1P2」ないし「S2P2」のシナリオに近い可能性があります。
P2シナリオは、行政の介入により、P1に比べ接触数を半減するシナリオです。より多くの検査が実施されることで検査カバー率が上昇しているとしたら、報告ベースの新規感染数が安定して推移するのは、実態の微減を示す可能性があります。報告ベース死亡者数が2ヶ月間ほど上昇を続けていますが、これが単なるタイムラグか、発見比率が増えたのか、振動しながら均衡に向かうのか、などは今後の展開を見守るところです。
8. まとめ
最後に、実態と報告数の違いについて考察です。この論文の第一のポイントは、新型コロナウィルスに関して報告される数値は、感染者数であれ、死者数であれ、一部の確認された範囲内に過ぎないということです。こうした知見は、イラン以外でも欧州各国や日本などで、抗体検査による感染者数が報告数よりも多い、という事実からも裏付けられています。その原因として挙げられるのは次のようなことがあります。
●市民がウィルスに関する知識やリスク認識が低いとそもそも自覚しない
●認識はあっても無症状あるいは軽症のため自覚しにくい
(一般に風邪で検査のため通院する人は1割もいない)
●患者が感染の可能性を疑っても検査を受ける上でのバイアスが存在する
(検査キャパシティの限度および限度があるゆえ試験要件に関するプライオリティ、海外では保険制度や本人の財務状況も影響)
●検査を受けても偽陰性など試験の精度に限界がある(PCR法でも3-5割は漏れる)
●感染の時点から発症、検査による陽性確認、報告までのタイムラグ(時間的遅れ)
論文の第二のポイントは、上述した実態と報告の乖離についてモデル化し、サンプルとして得られたデータからパラメーター較正することによって、実態の感染者数の確率的な分布を時間展開の元で推定できることです。また、必要な情報をサンプリングベースであっても時間展開上適宜データを取得することで、報告ベースではなく、推定する実態ベースの感染者数や死者数を把握することができます。
論文筆者は、3月20日時点でこのシミュレーションモデルを作成し、27日に発表したモデルをその後も使い続けて、その後の動態や政策効果を論じています。感染のように、爆発的に幾何級数的成長を遂げるダイナミクスに関する把握は、初期の状況認識によって大幅なズレを生み出す可能性があります。多くのシンクタンクが発表する、単純な正規分布の回帰分析に頼るのではなく、システムモデルによる分析が初期の不確実な状況化において、その不確実性の幅を的確に絞り込めることができます。
そして、論文の第三のポイントは、医療上や疫学上のパラメーターに加えて、市民、事業者、行政のリスク認識と結果としてとる検査、外出・接触、基本感染対策、隔離、社会的距離などの行動のパラメーターについて、より精度の高い政策決定の議論や効果のモニタリングが可能になります。とりわけ、感染のようにタイムラグが不可避でありながら、迅速な判断や行動がその成否を決める課題において、先行指標となりうるパラメーターを特定し、定期モニタリングあるいはサンプリングベースで情報を取得する付加価値は大きいでしょう。
今回の記事で取り上げた報告と実態の乖離、歪み、遅れの問題は、新型コロナウィルスに限るものではなく、組織や社会における課題に関する検討において極めて多くのケースで存在します。行政などへの報告が100%把握されていることは例外的で、むしろ通常はサンプリングデータでしかないくらいの認識を持つのがよいでしょう。そうした公式データに補足データを加えたシステム的な全体像の把握を行い、さらには、時間展開の中でのダイナミックな動態の把握や介入効果のシミュレーション及びモニタリングのデザインを考えることが有用と考えます。
(以上)
(文:小田理一郎)












